
TL;DR – I helped create a new model to assess goaltending talent based on simulating each goalie’s career-to-date expected goals 10,000 times and seeing how unlikely their actual results were after each career game. You can see the final visualization here.
How I got into this mess…
This past summer I embarked on a series of posts exploring how a simple statistical test might be useful in assessing early-career goaltending performance. I spoke briefly about the shortcomings of the analysis — a) for convenience I used all-situations save percentage, b) I used a semi-arbitrarily chosen SV% to assess results vs. ‘starting’ goalies, etc etc. But I thought it was a novel way to think about goaltending talent in small samples (treating every shot as a weighted coin flip) and I’d encourage you to check it out.
Anyways, I intended to keep exploring the thought in more posts but I proceeded to get clobbered by the Fall term — I’m nearing the end of another Masters degree (MSc in Analytics from Georgia Tech) and one of the core courses on data visualization was quite nasty (javascript is an evil walking this earth). To top off the stressful mess, there was a group project component to this course which any sane person would not exactly look forward to. But aye, there was a twist! You could literally do whatever you wanted as long as it involved data collection, data engineering, machine learning, and data visualization. PING. I had an idea.
I recruited a crack team of data nerds to come along with me on a journey of goaltending discovery. So I’ll give credit to them off the top — Saiem Gilani and Jeff Faath for data collection/engineering, Brian Haley for creating our Tableau visualization, and Spring Smith for editing our final paper. I handled the hockey nerdery, machine learning & statistical testing.
Using expected goals as our base unit of analysis…
I’m assuming you’re familiar with the concept of Expected Goals. It’s a concept I helped to birth through a series of now long-ago hacked posts on this blog back in 2013 — but the Wayback Machine has some remnants of my work here while some respected hockey analytics peeps’ opinions on my work at the time is still found here and here.
The idea behind Expected Goals was pretty simple. What’s the probability of a shot becoming a goal using its distance and shot type? I found the following image from a google image search from my original post in 2013 (love that Calibri font!). This was basically the chart that started it all:
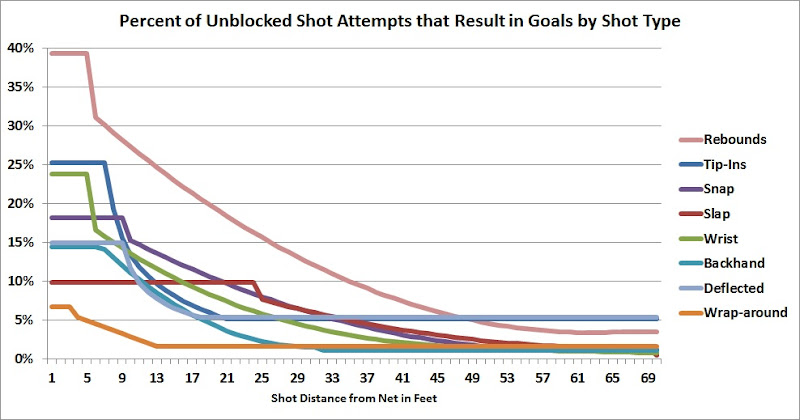
I used a fairly naive approach of simply looking at all past seasons of advanced shot events up to that point and plotting curves that seemed to fit the empirical data well. Generally, the farther away a shot is taken, the less chance it has of becoming a goal. Pretty easy right?
Well, since then, I’ve seen this original expected goals (xG) concept iterated and improved upon by many. The state-of-the-art models in the last few years have used advanced machine learning algorithms like logistic regression or gradient boosted trees to optimize the predicted probabilities on unseen data using a multitude of variables beyond mere distance and shot type. All good stuff.
Part of the reason I decided to do another Masters degree 2 years ago was to sharpen up my machine learning skills. For this project, I knew that getting our hands on a state-of-the-art expected goals estimate was paramount. Alas, most of the best ones are behind paywalls or haven’t really published their methodology or haven’t benchmarked themselves very well. But I did find this amazing post by evolving wild on their xG model that provided very handy benchmarks to gauge our model against.
Making a long story short, I built a new expected goals model using raw data found from MoneyPuck cross-stitched with box-score career player data from hockey-reference. Huge shout out to MoneyPuck for making their data public like this — the behind-the-net-era crew never had anything like this :). And a huge shout-out to my data engineers Saiem and Jeff for helping to get the data joined across multiple sources so that we had 197 features for every single shot event since 2007-08.
I proceeded to build an XGBoost model in python using this data. I then benchmarked my models to the ones published by Evolving Wild in the above link — they very courteously provided the log loss scores of their models using the 2017-18 data as unseen benchmarks. Now, I could only tune my hyperparameters for hours instead of days like the Evolving Wild guys did (damn you expensive AWS EC2 instances!), but I was happy that we got our log loss scores to within very close spitting distance of theirs, as seen below (lower is better):

So to summarize, creating the best expected goals model in the world wasn’t the primary goal of this project, but we definitely wanted to ensure we had something very close to what I considered to be the best in the world in memory. For what you ask?
Translating Expected Goals into something new for goalie analysis…
Ok, so we’ve got Expected Goals — remember, this is a probability of any shot going into the net given the 197 things we knew about that shot the moment it was released. A shot might have a 1% chance of going it, or a 10% chance, or a 48% chance. Why do we even care? Well, imagine a goalie (say, any goalie employed by the Oilers in the last decade) who is likely facing a higher proportion and/or absolute number of 48% chance shots than his peers. He’s probably going to be letting in more goals than they would. This added context makes xG something inherently more useful than raw save percentage in assessing goaltending talent.
And each goaltender has faced an entirely unique set of shots in their career — they’ve traversed their own personal trial by fire that is different than the career path of any other goalie. I want a model that’s going to tell each goaltender’s unique story at any point in their careers.
So, imagine any goalie’s career-to-date as a series of shots, each with a probability. 1%, 8%, 2%, 20%, 4%, 0.5%, 3%, etc etc etc. Imagine each of these as a weighted coin flip — for the first shot, 1 out of every 100 will go in — on average.
Now, what would happen if we could replay each shot taken an arbitrarily large number of times: say, 10,000 times? Take the 1% xG shot — it would go in around 100 times during these 10,000 simulations — 1% of the time it will be a goal, 99% of the time it won’t.
Now imagine simulating each shot in a goalie’s career 10,000 times, and adding up the number of times the simulations resulted in the goalie letting in various number of goals. For a goalie that has faced 1000 shots, some simulations would expect him to have let in 70 goals, some simulations would expect 90 goals, some crazy rare instances may even see him only letting in 20 goals. The idea is that we’re going to add up the results of all of these simulations to build a probability distribution for each goaltender… and then build this kind of distribution after every game of that goalie’s career…. for all goalies who’ve faced shots since 2007-08. That’s a lot of simulations!
An example, shall we?
This all sounds very academic, so let’s give this methodology some real life context. Let’s pick a goaltender that literally no one on Earth has either negative or positive biases towards — how about Louis Domingue? He’s played for… who… various teams? Whatever, he’ll do.
The distribution I described above (basically adding up the goals you’d expect after a certain number of specific shots that a goalie has faced up to that point in his career) can be described as a probability mass function, or PMF. Up to the end of last season (2018-19) Domingue had played in 123 games. Given the xG of all of the shots he’d faced in those 123 games, we can simulate them 10,000 times and see how often we’d expect various numbers of goals against. In the PMF graph below, you can see the results of these simulations:

After these 123 games, Domingue had actually let in 327 goals. But we can see that the mean expectation (the top of the bell curve) would have been around 312 goals. Ok, so Domingue has let in about 15 more goals than the average expectation given each shot’s xG. How bad is this?
The PMF allows us to setup rejection regions: the first would be to the far left of the graph in the low numbers of goals allowed, the second would be to the far right of this graph in the high numbers of goals allowed. Let’s semi-arbitrarily set the first region at the lowest 5% of simulated goals against. If Domingue found himself in this region (286 or less goals in this case), we would reject the hypothesis that he’s an average goalie and conclude that he is better than the average goalie (or ‘good’). The opposite is true: if Domingue allowed a number of goals that found him in the top 5% of simulations (in this case, 340 or more goals), we would conclude that he’s worse than the average goalie (or ‘bad’).
Because Domingue actually let in 327 goals, he’s between these two rejections regions, therefore we don’t have enough evidence to conclude that he’s either ‘good’ or ‘bad’ — we’ll stick with our null hypothesis that he’s an average NHL goalie.
So how unlikely is his 327 goals? Let’s look at a graph that’s very related to the probability mass function: the cumulative distribution function (or CDF).

Beautiful! So how does the CDF relate to the PMF? Basically, the CDF graph is a running total of the PMF. Domingue’s 327 actual goals rests at 0.816 on the CDF — this means that 81.6% of the 10,000 simulations resulted in the average goalie allowing less goals than he did, while 18.4% of simulations resulted in the average goalie allowing more goals than he did. I’m going to refer to the 81.6% as having a CDF score of 0.816 — the higher this score, the worse you’re doing versus expectations.
Think of it this way — the closer you get to either 0 or to 1, the more unlikely you are of being an average NHL goaltender who has just happened to put up unlikely numbers by chance. At some point we have to say “this is just too unlikely to be average, let’s call it here”. Here, we’ve set that boundary at the lowest and highest 5% of possibilities.
And let’s think about what ‘average’ means here for a second. The underlying unit of this analysis is Expected Goals. xG models are trained using all NHL shots. Who faces all NHL shots? What is the average shot faced? Because teams generally play their better goalies more than their bad ones (and star goalies more than non-stars), the average NHL shot is very likely faced by a better than average goalie. So deviating from the ‘average’ goalie in this model is actually deviating from a theoretical composite goalie who’s faced every single NHL shot, not the average goalie from a lineup of all goalies who’ve played NHL games.
As an aside, I don’t really have a funky name for this like Expected Goals. Maybe Average Goaltender Probability (AGP)? I’ll take your suggestions :).
Now that I’ve outlined this for his game 123, there’s no reason we can’t apply this test to every game of Domingue’s career:

Check out this link to see the above line for any goalie. You can hover over his line to see what his CDF score would have been at any point in his career along with its associated PMF graph.
For Domingue, we can see that he has never had a game where he wades into either the red ‘bad’ rejection region or the green ‘good’ rejection region. He certainly gets close to both at various points in his career, but we could have never rejected the idea that he’s an average NHL goalie at a 90% level of confidence (again, this is all as of the end of last season, and I see he’s had some poor games so far this year that might bump him up in to the red region).
Using the above link, you can explore literally any goalie that’s played a game since 2007-08. We put a ‘veteran’ tag on any goalie who played games before 2007-08 and therefore the first game is not his actual first career game but the first game of the 2007-08 season (Martin Brodeur’s line after this point would not have helped his case for the Hall of Fame, for instance).
In future posts I’ll be outlining some results of this methodology. How many goalies reach the rejection regions? How meaningful is reaching those regions? Once hitting those regions, do goalies ever reach the other region? How early can we reach sustainable conclusions?
In my opinion, the primary benefit of this approach is to get signal on a goalie’s talent level as early as possible. There used to be an axiom in hockey stats that you needed 2500 shots (or ~100 games) before deciding on a goalie’s talent level. And that always seemed unsatisfactory to me — you could burn the better part of two seasons accruing that kind of sample size. In the eternal tug between exploration & exploitation of analytics, waiting 100 games seemed wayyy too long in the exploration phase.
If you could have known, say, after game 20 that a goalie’s results were poorer than you would have expected from an average NHL goalie, you could have avoided playing him those additional 80 games in favour of better options. Or, you could have known very early that a goalie showed promise and start gearing up for his next contract before he prices himself into a different tier.
Mike said: “As an aside, I don’t really have a funky name for this like Expected Goals. Maybe Average Goaltender Probability (AGP)? I’ll take your suggestions :).”
How about Goalie Voodoo Debunker (GVD)
I think MacT said he had a GVD guy. 🙂
Awesome stuff Mike.
That is a great tool. Interesting to see that Mike Smith was a decidedly below average goal tender until game 200. Over the next 20 games he let in about 40 goals when he should have allowed about 70, and has been a good bet to be above average since then. I guess there’s still hope for Mikko yet. Thanks for sharing your work.
Incredibly good! Thanks so much
How many shots did Domingue face in those 123 games?
Please n thx.
Great work as always, Mike.
Thanks! If my arithmetic is correct, he faced 3578 shots on net in those games, but let me find the total of unblocked shots he faced, which is the unit of analysis here…
Great work but why did you claim to help birth expected goals? Your second link from respected hockey peeps says expected goals goes back to 2006 and Ken Krzyncki. And his paper says it goes back to Alan Ryder in 2004. It looks like expected goals was around and in use for almost a decade before your work.
The key innovation was tying it to on-ice player evaluation. On-ice events couldn’t even be attributed to players until 2007, so prior research was about general analysis of shots becoming goals. Delta wasn’t expressed as a probability that could then be aggregated into an expectation of goals. I coined the term ‘expected goals’ with respect to this kind of analysis (it had been used for kinds of analyses previous to my work). I was the first to test its relevance to concepts of true team strength. And I can confidently say that I was the first data analyst to regularly champion and apply this approach through my blog and Twitter at the time. All research builds on the ideas of others. I’m proud of my contribution to the general hockey body of knowledge in this case.